It is often a underestimate feature on Oracle Databases (changed a little bit with Exadata), Resource Manager is a very powerful feature that allows you to manage different workloads within a database. As you know hardware resources are limited and it is often necessary the proper allocation of resources to different tasks so it is Resource Manager job to handle these common problems these days.
This post will cover only CPU allocation (in a simple way) to different tasks or users. Understand the basis of CPU allocation from Resource Manager point of view will help to define a better plan to handle a proper allocation of your CPU resources.
Resource Manager is made of three components: consumer group, plan directives and resource plans.
Basically the consumer group is a group that aggregates and share common priority and scheduling. As example, in a datawarehousing evironment a “Reporting” group will share the same business priority.
In other way, plan directives is a link between a consumer group and a resource plan. It allows you to define the resource allocation. It is a one-to-one relationship and is a list of dictionary key value attributes.
In the end, resource plan is a collection of directives that will determine how of resources are allocated.Only one resource plan is allowed per instance.
Please note before continue that this post is not intended to explain Resource Manager in detail.
1 – The setup and example
We will setup a fairly simple use case. Let’s pretend that we have a datawarehousing system that has the following business rules. These rules have different CPU allocation priorities, based on business requirements:
– DAILY_LOAD: Daily data-load from several OLTP databases;
– REPORTING: Reporting tasks and services;
– ADHOC_QUERY: Adhoc querys issued by users.
The following PL/SQL will create four consumer groups that will allow us to respect business priorities. The CPU priority will be defined at plan directive creation.
BEGIN
dbms_resource_manager.clear_pending_area();
dbms_resource_manager.create_pending_area();
dbms_resource_manager.create_consumer_group(
consumer_group => 'DAILY_LOAD',
comment => 'Consumer group for critical OLTP applications');
dbms_resource_manager.create_consumer_group(
consumer_group => 'REPORTING',
comment => 'Consumer group for long-running reports');
dbms_resource_manager.create_consumer_group(
consumer_group => 'ADHOC_QUERYS',
comment => 'Consumer group for adhoc querys');
dbms_resource_manager.validate_pending_area();
dbms_resource_manager.submit_pending_area();
END;
Apart from this let’s create three difference services and one particular database user to ensure the following mapping.
BEGIN
dbms_resource_manager.clear_pending_area();
dbms_resource_manager.create_pending_area();
dbms_resource_manager.set_consumer_group_mapping(
attribute => dbms_resource_manager.service_name,
value => 'S_DAILY_LOAD',
consumer_group => 'DAILY_LOAD');
dbms_resource_manager.set_consumer_group_mapping(
attribute => dbms_resource_manager.service_name,
value => 'S_ADHOC',
consumer_group => 'ADHOC_QUERY');
dbms_resource_manager.set_consumer_group_mapping(
attribute => dbms_resource_manager.service_name,
value => 'S_REPORTING',
consumer_group => 'REPORTING');
dbms_resource_manager.submit_pending_area();
END;
BEGIN
dbms_resource_manager_privs.grant_switch_consumer_group(
GRANTEE_NAME => 'ROLE_DW',
CONSUMER_GROUP => 'DAILY_LOAD',
GRANT_OPTION => FALSE);
dbms_resource_manager_privs.grant_switch_consumer_group(
GRANTEE_NAME => 'ROLE_DW',
CONSUMER_GROUP => 'ADHOC_QUERY',
GRANT_OPTION => FALSE);
dbms_resource_manager_privs.grant_switch_consumer_group(
GRANTEE_NAME => 'ROLE_DW',
CONSUMER_GROUP => 'REPORTING',
GRANT_OPTION => FALSE);
END;
The mapping defined is the following:
– Users that connect to service S_DAILY_LOAD, S_ADHOC or S_REPORTING will be switched to the corresponding consumer group. Please note that all users that connect to application have the role ROLE_DW, avoiding specifing each individual database username.
– The last PL/SQL block will grant user that their session is able to switch to consumer group. This is mandatory for DBRM to be able to automatically switch your session. Even if you have a mapping that is based on service_name, module_name, client_os_user etc, your grant to switch need to be at username level. I’ve had a little discussion on this topic with Martin Bach during OUGN14 and so far is the only way to do it.
The next step is to create the plan and the plan directive. As it is a simple example, it is basically one plan and some directives for each consumer group.
BEGIN
dbms_resource_manager.clear_pending_area();
dbms_resource_manager.create_pending_area();
dbms_resource_manager.create_plan(
plan => 'DW_PLAN',
comment => 'Resource plan for normal business hours');
dbms_resource_manager.create_plan_directive(
plan => 'DW_PLAN',
group_or_subplan => 'DAILY_LOAD',
comment => 'DW Daily load from OLTP',
mgmt_p1 => 65);
dbms_resource_manager.create_plan_directive(
plan => 'DW_PLAN',
group_or_subplan => 'REPORTING',
comment => 'Reporting services and tasks - Lower priority',
mgmt_p2 => 50);
dbms_resource_manager.create_plan_directive(
plan => 'DW_PLAN',
group_or_subplan => 'ADHOC_QUERY',
comment => 'Adhoc Querys by users',
mgmt_p2 => 40);
dbms_resource_manager.create_plan_directive(
plan => 'DW_PLAN',
group_or_subplan => 'OTHER_GROUPS',
comment => 'All other groups',
mgmt_p3 => 100);
dbms_resource_manager.validate_pending_area();
dbms_resource_manager.submit_pending_area();
END;
2 – The formula for CPU plan allocation
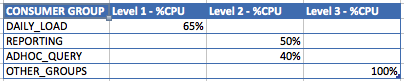
In the previous setup, we decided to specify the following CPU percentages for each task. As you can see, you can’t simply sum all the values at they are at different levels (mgmt_pN) and the sum of all values is over 100% of CPU allocation.

The formula for calculation CPU allocation of each level is the following:
Level N = (100 – SUM(L1)) x (100 – SUM(L2)) x (100 – SUM(L3)) … x Level N
Please note that for Level 1 or mgmt_1 there is not formula needed, just the value you setup in mgmt_p1.
In our case, the calculations are:
Level 1 (DAILY_LOAD) = 65%
Level 2 (REPORTING) = (100 – 65%) x 50% = 17,5%
Level 2 (ADHOC_QUERY) = (100 – 65%) x 40% = 14%
Level 3 (OTHER_GROUPS) = (100-65%) x (100% – SUM(50%+40%)) x 100% = 3,5%
Above is the summary of real CPU allocation, with a total of 100%. That means that all of CPU resources will be distributed across your priority and preferences. Of course, getting a perfect match between the CPU allocation that you setup and the real case scenario can be fairly difficult but a very approximate value is expected. Part 2 of these article will be focused on doing some test trying to measure a real case scenario.

Have a nice weekend.